
TL;DR:
- Most startups mistakenly scale early, risking wasted resources and operational failures without validation. Validating demand, solution fit, and operational readiness ensures sustainability and reduces costly mistakes. Ongoing discipline in validation protects growth efforts and adapts to market shifts over time.
Most startup teams believe that moving fast and scaling hard is how you win. Build fast, hire fast, spend fast. The problem is that scaling too early wastes capital, overbuilds teams, and creates operational pressure that compounds every week you ignore it. Validation is not a bureaucratic checkpoint. It is the work that tells you whether you have a real signal worth amplifying or just noise that will cost more to clean up the louder it gets. This article breaks down exactly why validate before scaling is the discipline that separates funded failures from sustainable growth.
Table of Contents
- Key Takeaways
- Why validate before scaling: the phases that matter
- The real costs of skipping validation
- How to validate fast without building too much
- Operational readiness as a validation gate
- My perspective on why this keeps going wrong
- Ready to validate before you commit to building?
- FAQ
Key Takeaways
| Point | Details |
|---|---|
| Validation confirms real demand | Retention, repeat usage, and willingness to pay are the signals that actually matter before you scale. |
| Skipping phases is expensive | Rushing through problem, solution, or market-fit phases compounds costs and weakens unit economics fast. |
| Scaling amplifies what exists | Weak product-market fit does not improve with more spend. It gets more expensive and harder to reverse. |
| Behavioral metrics beat vanity metrics | Unprompted usage and who would miss your product reveal fit far better than signup counts or page views. |
| Readiness covers operations too | Infrastructure capacity, error rates, and routing health must clear defined thresholds before any scale-up. |
Why validate before scaling: the phases that matter
Before you can scale anything sustainably, you need to pass through four distinct validation phases. Most founders collapse these into one. That collapse is where the waste begins.
Phase 1: Problem validation. You need evidence that the problem you are solving is real, frequent, and painful enough for someone to pay to fix. Conversations work here. Surveys do not. You want behavioral evidence, not people agreeing with your idea to be polite.
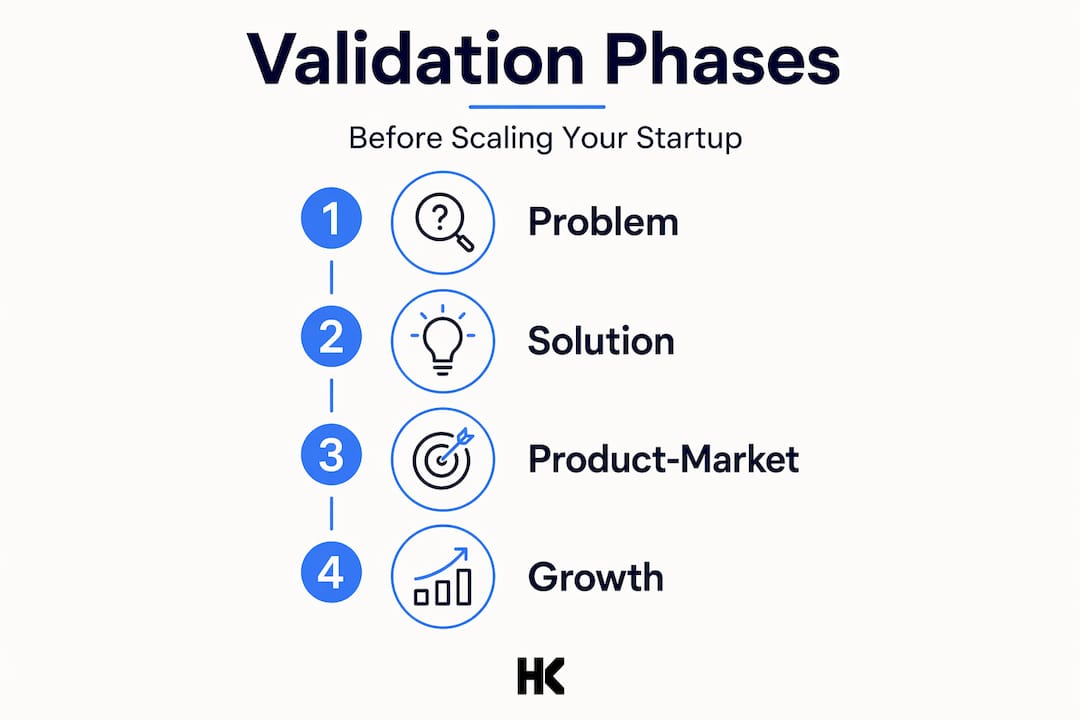
Phase 2: Solution validation. You have a proposed fix. Now you test whether your solution actually resolves the problem better than what people already use. This is where small, fast MVP experiments focused on riskiest assumptions reduce validation theater and increase learning that you can act on.
Phase 3: Product-market alignment. This is the phase most teams rush. You are looking for a specific behavioral cluster: retention that holds without pushing, users who return unprompted, and a segment that would be genuinely upset if your product disappeared tomorrow. NPS scores alone are insufficient. Segment clarity and strong behavioral signals are what actually indicate readiness for the next phase.
Phase 4: Scalable growth. Only here do you open the spend valve. You have repeatable acquisition, solid retention in a defined segment, and pricing that reflects real willingness to pay.
Here is what each phase requires before you move forward:
| Phase | Evidence required | Common mistake |
|---|---|---|
| Problem validation | Observed pain, frequency data, budget signals | Relying on survey responses instead of behavior |
| Solution validation | Usage of MVP, task completion, repeat access | Building full product before testing core hypothesis |
| Market alignment | Retention curves, segment fit, behavioral demand | Treating early-adopter enthusiasm as broad-market signal |
| Scalable growth | Repeatable CAC, strong cohort retention, pricing proof | Scaling marketing before retention is stable |
The importance of validation at each phase is not abstract. It is the difference between knowing you have a product people will pay for repeatedly and hoping you do.
The real costs of skipping validation
Here is the honest picture of what premature scaling looks like in practice. You have ten users who love your product. You raise a seed round and hire a growth team. Three months later, your customer acquisition cost has tripled and your 30-day retention has dropped from 45% to 19%. What happened?

Scaling spend amplifies current performance signals. When those signals are weak, you pay more for lower-quality users who churn faster. Performance marketing typically captures existing user intent rather than creating new demand, so when you move beyond your tight early-adopter base, CAC rises and retention deteriorates. You have not fixed a problem. You have made it louder and more expensive.
The operational damage runs deeper than a spreadsheet shows:
- Engineering teams get pulled into scaling infrastructure before the product is actually stable under real usage patterns.
- Customer success costs spike as a broader, less-fit user base requires more support per account.
- Investor pressure creates urgency to show growth metrics, which incentivizes more spend on an already-broken funnel.
- Re-hiring and re-training after the correction takes months, not weeks.
Pro Tip: Watch your week-4 retention cohort before any growth spend. If fewer than 25-30% of users are still active four weeks after signup, you do not have a retention story that will survive scale.
The risks of unvalidated scaling are not theoretical. They are the normal outcome of moving the acquisition lever before the retention lever is working. Premature scaling raises CAC, softens retention, and degrades unit economics in a sequence that is hard to reverse once teams, contracts, and infrastructure are locked in.
How to validate fast without building too much
The goal of validation is not certainty. It is speed of disproof. Validation is the effort to prove you are wrong quickly, reducing uncertainty before committing significant resources. That reframe changes everything about how you approach it.
Here is a practical sequence for software startups:
- Write your riskiest assumption down. Not the problem. The assumption underneath the problem. "Users will check this tool daily without being reminded" is a testable assumption. "People want better project management" is not.
- Design the smallest test that can disprove it. A landing page with a waitlist tests demand. A manual concierge service tests willingness to pay. A no-code prototype tests whether users can complete the core task. You can run these in days or weeks, not quarters.
- Measure behavior, not sentiment. Did they come back? Did they complete the action? Did they pay without being asked twice? Actionable, behavioral metrics beat signup counts every time.
- Run the Build-Measure-Learn loop fast. Build the smallest thing that tests the hypothesis. Measure what users actually do. Learn and update your assumptions. Then repeat. Speed matters here because each cycle costs real time and money.
- Kill failed hypotheses cleanly. This is the step most teams skip. When an experiment disproves your assumption, document it and update your model. Do not pivot the framing to save the hypothesis.
Pro Tip: Set a 2-week time box per experiment. If you cannot design and run a test in two weeks that gives you disprovable results, the experiment is too large. Break it down.
You can read a deeper breakdown of how this applies to specific product bets in the SaaS idea validation guide at Hanadkubat. The steps to validate ideas mapped there mirror this loop with concrete SaaS-specific examples.
Understanding user behavior to optimize your content and growth strategy is a related discipline that complements product validation, especially once you start testing acquisition messaging alongside product experiments.
Operational readiness as a validation gate
Product-market fit is not the only thing that needs validation before you scale. Your infrastructure does too. This matters more than most product teams admit until something breaks publicly.
Readiness verification requires validating capacity, routing health, warm-up stability, and dependency metrics before scaling to prevent user impact and operational failures. Reactive autoscaling fails under sudden demand spikes because by the time it triggers, users are already experiencing errors. Predictive scaling, based on validated capacity models, prevents that window entirely.
Before any scale-up event, your team should confirm the following:
- Fleet capacity health: At least 95% of target nodes are healthy and responding within acceptable latency thresholds.
- Cache warm-up stability: Caches are pre-loaded and hit rates are at expected levels, not cold-start behavior.
- Error rate baselines: Upstream and downstream error rates are within normal bounds, not trending upward in the days before scale.
- Dependency saturation: No downstream service is already near its capacity ceiling before you add load.
| Readiness signal | Threshold before scaling | Risk if ignored |
|---|---|---|
| Target capacity health | ≥95% of nodes healthy | Uneven load distribution, cascade failures |
| Upstream error rate | Within normal baseline | Error amplification under load |
| Cache hit rate | At expected steady-state | Latency spikes on first traffic surge |
| Downstream saturation | No service above 70% capacity | Dependency failures under new load |
A validated solution reduces risk, speeds deployment confidence, and increases reliability before large-scale rollouts. Treating infrastructure readiness as a one-time checklist instead of a repeatable gate is how outages happen on your most important growth days.
The MVP validation checklist at Hanadkubat includes both product and technical readiness signals worth reviewing before any planned scale-up.
My perspective on why this keeps going wrong
I have worked with enough early-stage teams across DACH and beyond to see the same pattern repeat. The pressure to show growth to investors, co-founders, or the team itself creates a bias toward motion. Scaling feels like progress. Validation feels like delay.
What I have seen in practice is the opposite. The teams that spent four extra weeks validating their retention hypothesis before scaling acquisition saved six-to-twelve months of painful correction work afterward. The teams that scaled on enthusiasm instead of evidence spent that same period rebuilding funnels, replacing hires, and re-explaining to investors why the numbers reversed.
My honest take: most early scaling decisions are confidence substitutes. You scale because you want to believe the product is ready, not because the data says it is. Confirming demand, pricing, user behavior, and repeatability before scaling is not conservative thinking. It is the only approach that actually protects your resources and your team's time.
The other thing I would push back on is treating validation as a phase you complete. It is not. Fit degrades. Markets shift. What worked for your first 200 customers may not work for your next 2,000. Validation is an ongoing discipline, not a milestone you check off and forget. I have built and shipped my own SaaS products end-to-end and that lesson cost me real time before I internalized it.
— Hanad
Ready to validate before you commit to building?
If you are a non-technical founder or early-stage product team trying to figure out whether your idea is worth building, or whether your current product is ready to scale, Hanadkubat offers a structured way in. The €1,500 strategy sprint scopes and validates your idea before a single line of code is written. It covers problem validation, solution framing, and technical feasibility in a focused engagement that takes weeks, not months.
For teams that have already built and need to confirm readiness before a growth push, the product validation guide is a practical starting point. And if you are ready to discuss your specific situation directly, pricing and service details are at hanadkubat.com. You work with the engineer who ships the code, not a hand-off chain.
FAQ
Why validate before scaling instead of just iterating after?
Scaling before validation amplifies weak signals into expensive problems. Iterating after scaling costs far more in CAC, team time, and lost retention than the validation work would have upfront.
What signals actually confirm product-market fit?
Retention without prompting, repeat usage, willingness to pay without discounting, and users who would be genuinely upset if the product disappeared are the most reliable behavioral signals.
How long should validation take before scaling?
There is no fixed timeline, but most teams need four to twelve weeks of real behavioral data per phase to draw conclusions worth acting on. Rushing this is where the waste begins.
What is the biggest mistake teams make during validation?
Collecting confirming anecdotes instead of running experiments designed to disprove their core assumptions. Real validation means designing tests you can fail, not gathering evidence that you are right.
Does infrastructure need validation before scaling too?
Yes. Capacity health, error rate baselines, and dependency saturation all need to clear defined thresholds before a scale event, or operational failures become likely under the new load.